ETL-процессы: что это такое, принципы работы и примеры реализации для небольших компаний
Введение в ETL-процессы
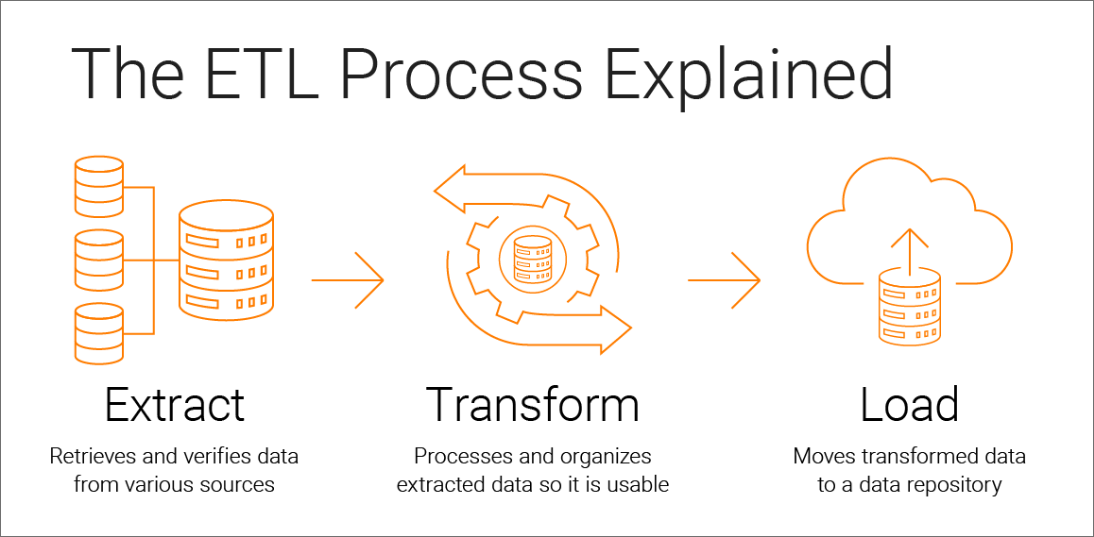
ETL (Extract, Transform, Load) — это набор процессов, позволяющих извлекать данные из источников, преобразовывать их в нужный формат и загружать в целевое хранилище для последующего анализа.
Основные компоненты ETL-процесса
1. Извлечение данных (Extract)
Процесс извлечения данных включает в себя считывание информации из различных источников. Данные могут храниться в разных форматах и системах:
- Реляционные базы данных (MySQL, PostgreSQL, MS SQL Server)
- Файлы (CSV, Excel, JSON, XML)
- API-интерфейсы внешних сервисов
- CRM-системы и ERP-решения
- Веб-сайты и социальные сети
- Локальные приложения
На этом этапе важно правильно настроить параметры подключения, учесть ограничения по объему и частоте выгрузки данных, а также обеспечить безопасность передачи информации.
2. Преобразование данных (Transform)
После извлечения данных наступает этап их трансформации — приведения к единому формату и структуре для дальнейшего анализа. Среди типичных операций преобразования:
- Очистка данных (устранение дубликатов, обработка пропущенных значений)
- Нормализация и стандартизация (приведение к единым форматам дат, адресов, телефонов)
- Агрегация (суммирование, вычисление средних значений)
- Обогащение данных (добавление дополнительной информации)
- Фильтрация (удаление нерелевантных данных)
- Объединение данных из разных источников
- Вычисление производных показателей
Для небольших компаний особенно важно сосредоточиться на преобразованиях, которые непосредственно влияют на бизнес-решения, избегая излишней сложности.
3. Загрузка данных (Load)
Заключительный этап — загрузка преобразованных данных в целевое хранилище:
- Хранилище данных (Data Warehouse)
- Витрины данных (Data Marts)
- Аналитические базы данных
- Озера данных (Data Lakes)
- Системы бизнес-аналитики (BI)
Загрузка может быть полной (перезапись всех данных) или инкрементальной (добавление только новых или измененных данных). Для небольших компаний инкрементальная загрузка часто предпочтительнее, так как требует меньше ресурсов.
Принципы построения эффективных ETL-процессов
1. Автоматизация и планирование
Эффективные ETL-процессы должны выполняться автоматически по расписанию. Для небольших компаний оптимально настроить выполнение в непиковые часы нагрузки на бизнес-системы, например, ночью или в выходные дни.
2. Отказоустойчивость и обработка ошибок
ETL-процессы должны корректно обрабатывать различные сценарии сбоев: недоступность источников данных, ошибки в структуре данных, проблемы сетевого соединения. Важно реализовать механизмы логирования и уведомлений для оперативного выявления и устранения проблем.
3. Масштабируемость
Даже для небольших компаний важно учитывать рост объёма данных с течением времени. ETL-решение должно быть способно обрабатывать увеличивающиеся объемы информации без существенного изменения архитектуры.
4. Мониторинг и аудит
Регулярный мониторинг производительности ETL-процессов и аудит данных помогают выявлять узкие места и обеспечивать высокое качество информации.
5. Документирование
Подробная документация по ETL-процессам — критически важный аспект, особенно для небольших компаний, где часто один специалист отвечает за всю инфраструктуру данных.
Инструменты для реализации ETL-процессов в малом бизнесе
Бюджетные решения с открытым исходным кодом
1. Apache NiFi
NiFi предоставляет интуитивно понятный веб-интерфейс для визуального проектирования потоков данных. Он хорошо подходит для небольших компаний благодаря:
- Низкому порогу входа (не требует глубоких знаний программирования)
- Обширной библиотеке готовых компонентов
- Возможности работы на скромных аппаратных ресурсах
- Надежной обработке ошибок и их логированию
2. Talend Open Studio
Talend предлагает бесплатную версию своего ETL-инструмента с графическим интерфейсом, который позволяет:
- Использовать готовые коннекторы для популярных источников данных
- Создавать сложные преобразования без написания кода
- Отлаживать и тестировать ETL-процессы
- Экспортировать процессы в автономные приложения
3. Pentaho Data Integration (PDI)
PDI (также известный как Kettle) предоставляет мощные возможности для интеграции данных:
- Интуитивно понятный графический интерфейс
- Поддержка большого количества источников и форматов данных
- Возможность создания комплексных ETL-процессов
- Интеграция с другими компонентами Pentaho BI Suite
Облачные решения
1. AWS Glue
Для компаний, использующих инфраструктуру Amazon Web Services:
- Бессерверный сервис (оплата только за фактическое использование)
- Автоматическое обнаружение схемы данных
- Генерация кода ETL на Python или Scala
- Интеграция с другими сервисами AWS
2. Google Cloud Dataflow
Подходит для бизнеса, работающего с экосистемой Google:
- Обработка как пакетных, так и потоковых данных
- Авторазмещение и автомасштабирование
- Интеграция с BigQuery и другими сервисами Google Cloud
- Возможность использования готовых шаблонов ETL
3. Microsoft Azure Data Factory
Оптимально для компаний, использующих технологии Microsoft:
- Визуальное проектирование ETL-процессов
- Гибридная интеграция (облако + локальные данные)
- Обширная библиотека соединителей
- Интеграция с Power BI и другими сервисами Azure
Программные решения для начального уровня
1. Python с библиотеками pandas и SQLAlchemy
Для компаний с ограниченным бюджетом, имеющих в штате специалистов по Python:
- Низкая стоимость (бесплатные библиотеки с открытым исходным кодом)
- Гибкость в реализации любых преобразований
- Простота интеграции с различными источниками данных
- Возможность автоматизации через планировщик задач (cron, Windows Task Scheduler)
2. SQL Server Integration Services (SSIS)
Для компаний, уже использующих Microsoft SQL Server:
- Включено в стандартную лицензию SQL Server
- Мощные возможности для трансформации данных
- Визуальный конструктор потоков данных
- Тесная интеграция с другими продуктами Microsoft
Примеры реализации ETL-процессов для небольших компаний
Пример 1: Консолидация данных о продажах
Задача:
Небольшой розничной сети требуется ежедневно консолидировать данные о продажах из офлайн-магазинов и интернет-сайта для формирования отчетов.
Решение на базе Python:
import pandas as pd
import sqlite3
from sqlalchemy import create_engine
import schedule
import time
import logging
# Настройка логирования
logging.basicConfig(filename='etl_sales.log', level=logging.INFO,
format='%(asctime)s - %(message)s')
def extract_data():
try:
# Подключение к базе данных офлайн-магазинов
offline_conn = sqlite3.connect('offline_store.db')
offline_sales = pd.read_sql("SELECT * FROM sales WHERE date = date('now', '-1 day')", offline_conn)
# Загрузка данных с онлайн-магазина через API
online_sales = pd.read_csv('https://example.com/api/sales/daily?date=yesterday&token=YOUR_API_TOKEN')
logging.info(f"Извлечено {len(offline_sales)} записей из офлайн-магазинов")
logging.info(f"Извлечено {len(online_sales)} записей из онлайн-магазина")
return offline_sales, online_sales
except Exception as e:
logging.error(f"Ошибка при извлечении данных: {str(e)}")
raise
def transform_data(offline_sales, online_sales):
try:
# Стандартизация структуры данных
offline_sales = offline_sales.rename(columns={
'sale_id': 'order_id',
'sale_date': 'date',
'total': 'amount'
})
online_sales = online_sales.rename(columns={
'order_number': 'order_id',
'created_at': 'date',
'price': 'amount'
})
# Добавление источника данных
offline_sales['source'] = 'offline'
online_sales['source'] = 'online'
# Объединение данных
all_sales = pd.concat([offline_sales, online_sales])
# Очистка данных
all_sales['date'] = pd.to_datetime(all_sales['date'])
all_sales['amount'] = all_sales['amount'].astype(float)
# Добавление дополнительных аналитических полей
all_sales['day_of_week'] = all_sales['date'].dt.day_name()
all_sales['month'] = all_sales['date'].dt.month_name()
logging.info(f"Преобразовано {len(all_sales)} записей")
return all_sales
except Exception as e:
logging.error(f"Ошибка при преобразовании данных: {str(e)}")
raise
def load_data(all_sales):
try:
# Подключение к хранилищу данных
engine = create_engine('postgresql://username:password@localhost:5432/data_warehouse')
# Загрузка данных
all_sales.to_sql('sales_fact', engine, if_exists='append', index=False)
logging.info(f"Загружено {len(all_sales)} записей в хранилище данных")
except Exception as e:
logging.error(f"Ошибка при загрузке данных: {str(e)}")
raise
def etl_process():
try:
logging.info("Начало ETL-процесса")
# Извлечение
offline_sales, online_sales = extract_data()
# Преобразование
all_sales = transform_data(offline_sales, online_sales)
# Загрузка
load_data(all_sales)
logging.info("ETL-процесс успешно завершен")
except Exception as e:
logging.error(f"ETL-процесс завершился с ошибкой: {str(e)}")
# Запуск ETL-процесса ежедневно в 3:00
schedule.every().day.at("03:00").do(etl_process)
if __name__ == "__main__":
while True:
schedule.run_pending()
time.sleep(60)Пример 2: Интеграция данных CRM и бухгалтерии
Задача:
Небольшой сервисной компании необходимо объединить данные из CRM-системы и бухгалтерского ПО для анализа эффективности продаж и прогнозирования денежных потоков.
Решение на базе Pentaho Data Integration:
-
Настройка источников данных:
- Подключение к API CRM-системы для извлечения данных о клиентах и сделках
- Настройка ODBC-соединения с бухгалтерской программой 1С
- Определение периодичности обновления данных (еженедельно)
-
Преобразование данных:
- Сопоставление клиентов в CRM с контрагентами в 1С
- Сопоставление сделок с платежами
- Расчет ключевых показателей (время закрытия сделки, средний чек, рентабельность)
- Создание аналитических измерений (менеджеры, регионы, категории услуг)
-
Загрузка в хранилище:
- Инкрементальная загрузка в локальное хранилище данных на базе PostgreSQL
- Создание витрины данных для отчетов в Power BI
-
Планирование и мониторинг:
- Настройка выполнения ETL-процесса по выходным
- Настройка email-уведомлений о результатах выполнения
- Ведение журнала изменений для аудита
Типичные проблемы при внедрении ETL в малом бизнесе и их решения
1. Ограниченный бюджет
Проблема: Малый бизнес часто не может позволить себе дорогостоящие коммерческие ETL-решения.
Решение:
- Использование инструментов с открытым исходным кодом
- Применение облачных решений с оплатой по мере использования
- Постепенное наращивание функциональности ETL-системы
2. Отсутствие специализированных кадров
Проблема: В малых компаниях редко есть штатные специалисты по данным.
Решение:
- Выбор инструментов с низким порогом входа и хорошей документацией
- Привлечение внешних консультантов для первоначальной настройки
- Инвестиции в обучение существующих IT-специалистов
3. Качество исходных данных
Проблема: Данные в системах малого бизнеса часто содержат ошибки и неточности.
Решение:
- Внедрение процедур проверки и очистки данных на этапе трансформации
- Разработка системы оповещений о проблемах с качеством данных
- Документирование правил обработки проблемных данных
4. Совместимость источников
Проблема: Интеграция разнородных систем и форматов данных.
Решение:
- Использование промежуточного слоя данных для стандартизации
- Применение ETL-инструментов с широким набором коннекторов
- Создание универсальных интерфейсов обмена (например, REST API)
Эволюция ETL-процессов в современной аналитике данных
От ETL к ELT
Современная тенденция — переход от классического ETL (Extract-Transform-Load) к модели ELT (Extract-Load-Transform), когда данные сначала загружаются в хранилище, а затем уже трансформируются. Этот подход имеет ряд преимуществ для малого бизнеса:
- Снижение сложности первоначальной настройки
- Возможность повторного использования исходных данных для разных аналитических задач
- Применение современных инструментов хранилищ данных для трансформации (например, SQL в BigQuery или Snowflake)
Потоковая обработка данных
Для бизнесов, требующих аналитики в режиме реального времени, становится актуальной потоковая обработка данных. Инструменты вроде Apache Kafka в сочетании с Apache Spark Streaming позволяют организовать непрерывную обработку данных с минимальной задержкой.
Датафикация бизнес-процессов
Небольшие компании все чаще внедряют датчики и устройства Интернета вещей (IoT) для сбора данных о своих процессах. Это создает новые требования к ETL-системам для обработки высокочастотных и разнородных потоков данных.
Заключение
ETL-процессы являются фундаментальным компонентом аналитической инфраструктуры даже для небольших компаний. Они позволяют консолидировать данные из разных источников, обеспечивая основу для бизнес-аналитики и принятия решений на основе данных.
Сегодня существует множество доступных инструментов и подходов для построения ETL-процессов, которые не требуют значительных финансовых вложений или глубоких технических знаний. Ключевым фактором успеха является выбор решения, соответствующего масштабу бизнеса, его техническим возможностям и перспективам роста.
Инвестиции в правильно организованные ETL-процессы окупаются за счет более эффективного использования данных, повышения качества аналитики и, в конечном итоге, более обоснованных бизнес-решений.